Movie Analytics Pipeline
What?
The project is a data engineering project about building a movie analytics pipeline. The data is stored in a MySQL database on AWS, where several views are created to combine information about movies, actors, genres, and roles. The goal of the project is to move this data through a complete data pipeline and make it useful for analysis.
How?
The project uses a medallion-style architecture. First, the data is extracted from the MySQL database and saved in an AWS S3 bucket as JSON files in a bronze layer. After that, the data is cleaned, normalized, and converted to Parquet files in a silver layer. A Python Flask API with DuckDB is then used to query the Parquet files directly from S3 and return the data to a website.
Conclusion
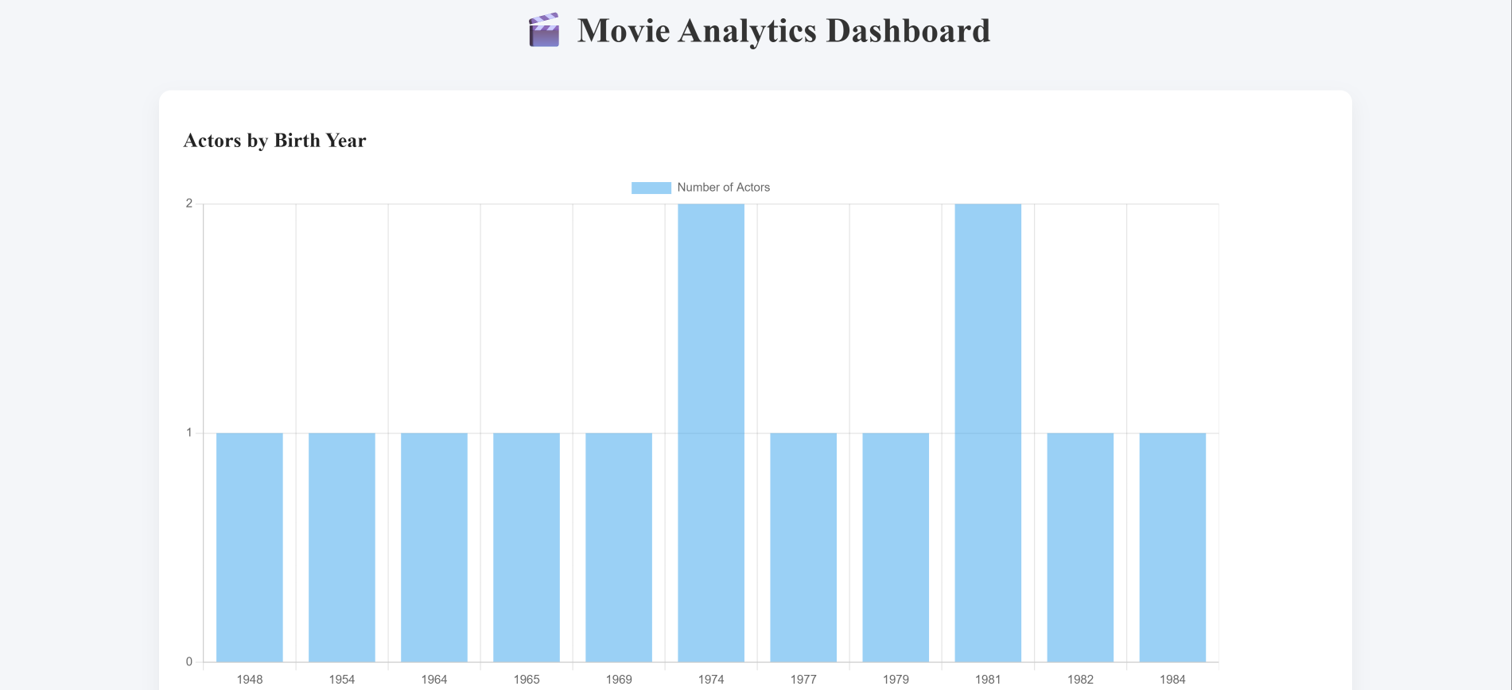
the project shows how raw database data can be transformed into clean, structured, and visualized information. By using AWS, S3, Python, Flask, DuckDB, and Chart.js, the project creates a scalable pipeline from ingestion to visualization. The final result is a movie analytics dashboard that makes the data easier to understand and explore.